使用115网盘搭建emby
使用开源工具连接115网盘生成strm和刮削图片
-
使用docker compose运行工具
version: "2.3" services: qmediasync: image: qicfan/qmediasync:latest container_name: qmediasync restart: unless-stopped ports: - "12333:12333" - "8095:8095" - "8094:8094" networks: - all volumes: - ./config/qmediasync:/app/config - ./strm:/media environment: - TZ=Asia/Shanghai networks: all: driver: bridge -
配置刮削和同步
- 打开
http://localhost:12333 - 配置刮削和同步
- 打开
安装emby server
-
使用快乐版
version: "2.3" services: emby: volumes: - ./config/emby:/config - ./strm:/data ports: - "8096:8096" networks: - all environment: - TZ=Asia/Shanghai # 推荐:省略 UID/GID=0,以非特权用户运行 # user: "1000:1000" # 如果需要指定用户,请使用非0的ID restart: always container_name: emby image: amilys/embyserver:latest -
配置反代
emby.xx.xx { # 匹配 /refresh 和 /action 开头的所有请求 @tools path /refresh /action/* handle @tools { reverse_proxy 127.0.0.1:18080 } # 其他转发给 Emby handle { reverse_proxy 127.0.0.1:8095 } } -
配置快速刷新媒体库的脚本
import subprocess from http.server import BaseHTTPRequestHandler, HTTPServer from urllib.parse import urlparse, parse_qs import requests # --- 配置区域 --- # Python 服务监听配置 HOST_NAME = "0.0.0.0" PORT_NUMBER = 18080 # Emby 配置 EMBY_BASE_URL = "https://emby.xx.xx" EMBY_API_KEY = "xx" # 脚本路径 SHELL_SCRIPT_PATH = "/root/update_blog.sh" # --- 功能函数 --- def get_emby_libraries(): """获取 Emby 所有媒体库列表""" url = f"{EMBY_BASE_URL}/Library/SelectableMediaFolders" params = {"api_key": EMBY_API_KEY} try: resp = requests.get(url, params=params) if resp.status_code == 200: return resp.json() # 返回列表数据 return [] except Exception as e: print(f"获取媒体库失败: {e}") return [] def refresh_emby_library(item_id): """调用 Emby API 刷新指定库""" url = f"{EMBY_BASE_URL}/Items/{item_id}/Refresh" params = { "api_key": EMBY_API_KEY, "Recursive": "true", "ImageRefreshMode": "Default", "MetadataRefreshMode": "Default", "ReplaceAllMetadata": "false" } try: resp = requests.post(url, params=params) if resp.status_code in [200, 204]: return True, f"✅ 刷新指令已发送 (ID: {item_id})" else: return False, f"❌ 失败: {resp.status_code} - {resp.text}" except Exception as e: return False, f"❌ 请求错误: {e}" def run_shell_script(): """执行本地 Shell 脚本""" try: result = subprocess.run([SHELL_SCRIPT_PATH], capture_output=True, text=True, check=True, shell=True) return f"✅ 脚本执行成功:\n{result.stdout}" except subprocess.CalledProcessError as e: return f"❌ 脚本执行出错 (Code {e.returncode}):\n{e.stderr}" except Exception as e: return f"❌ 未知错误: {e}" def get_html_page(message=None): """ 生成动态 HTML 菜单页面 message: 操作后的提示信息 """ # 1. 动态获取媒体库列表 libraries = get_emby_libraries() # 2. 生成媒体库按钮 HTML lib_buttons_html = "" if libraries: for lib in libraries: lib_id = lib.get('Id') lib_name = lib.get('Name') # 链接指向 /action/refresh?id=xxx&name=xxx lib_buttons_html += f'<a href="/action/refresh?id={lib_id}&name={lib_name}" class="btn">🔁 刷新 {lib_name}</a>\n' else: lib_buttons_html = '<p style="color:red">⚠️ 无法获取媒体库列表,请检查 API Key 或网络。</p>' # 3. 提示信息 HTML msg_html = f'<div class="alert">{message}</div>' if message else '' return f""" <!DOCTYPE html> <html> <head> <meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1"> <title>Emby 管理面板</title> <style> body {{ font-family: -apple-system, sans-serif; max-width: 600px; margin: 20px auto; padding: 20px; text-align: center; background-color: #f4f4f9; }} h1 {{ color: #333; margin-bottom: 20px; }} .card {{ background: white; padding: 30px; border-radius: 12px; box-shadow: 0 4px 15px rgba(0,0,0,0.1); }} .section-title {{ text-align: left; font-size: 14px; color: #888; margin-top: 20px; margin-bottom: 10px; font-weight: bold; text-transform: uppercase; letter-spacing: 1px; }} .btn {{ display: block; width: 100%; padding: 12px 0; margin-bottom: 10px; background: #007bff; color: white; text-decoration: none; border-radius: 8px; font-size: 16px; font-weight: 500; transition: background 0.2s; }} .btn:hover {{ background: #0056b3; }} .btn.secondary {{ background: #6c757d; }} .btn.secondary:hover {{ background: #545b62; }} .alert {{ background: #d4edda; color: #155724; padding: 15px; margin-bottom: 20px; border-radius: 8px; border: 1px solid #c3e6cb; }} </style> </head> <body> <div class="card"> <h1>🛠️ Emby 管理中心</h1> {msg_html} <div class="section-title">媒体库操作</div> {lib_buttons_html} <div class="section-title">系统操作</div> <a href="/action/update_blog" class="btn secondary">📝 更新博客脚本</a> <div style="margin-top: 20px; font-size: 12px; color: #ccc;"> <a href="/refresh" style="color: #ccc; text-decoration: none;">刷新页面</a> </div> </div> </body> </html> """ # --- HTTP 处理逻辑 --- class RequestHandler(BaseHTTPRequestHandler): def do_GET(self): # 解析 URL 和 参数 parsed_url = urlparse(self.path) path = parsed_url.path query_params = parse_qs(parsed_url.query) # 结果类似 {'id': ['708'], 'name': ['Movie']} response_content = "" # 1. 访问首页 if path == '/refresh': response_content = get_html_page() # 2. 动态刷新媒体库 /action/refresh?id=xxx elif path == '/action/refresh': lib_id = query_params.get('id', [None])[0] lib_name = query_params.get('name', ['未知库'])[0] if lib_id: success, msg = refresh_emby_library(lib_id) # 操作完成后,返回带有结果提示的首页 response_content = get_html_page(message=f"{lib_name}: {msg}") else: response_content = get_html_page(message="❌ 错误:缺少媒体库 ID") # 3. 更新博客 elif path == '/action/update_blog': msg = run_shell_script() response_content = get_html_page(message=msg) # 4. 404 else: self.send_response(404) self.end_headers() self.wfile.write(b"404 Not Found") return # 发送响应 (HTML) self.send_response(200) self.send_header("Content-type", "text/html; charset=utf-8") self.end_headers() self.wfile.write(response_content.encode('utf-8')) if __name__ == "__main__": server = HTTPServer((HOST_NAME, PORT_NUMBER), RequestHandler) print(f"Server started at http://{HOST_NAME}:{PORT_NUMBER}") try: server.serve_forever() except KeyboardInterrupt: pass server.server_close()
效果如下:
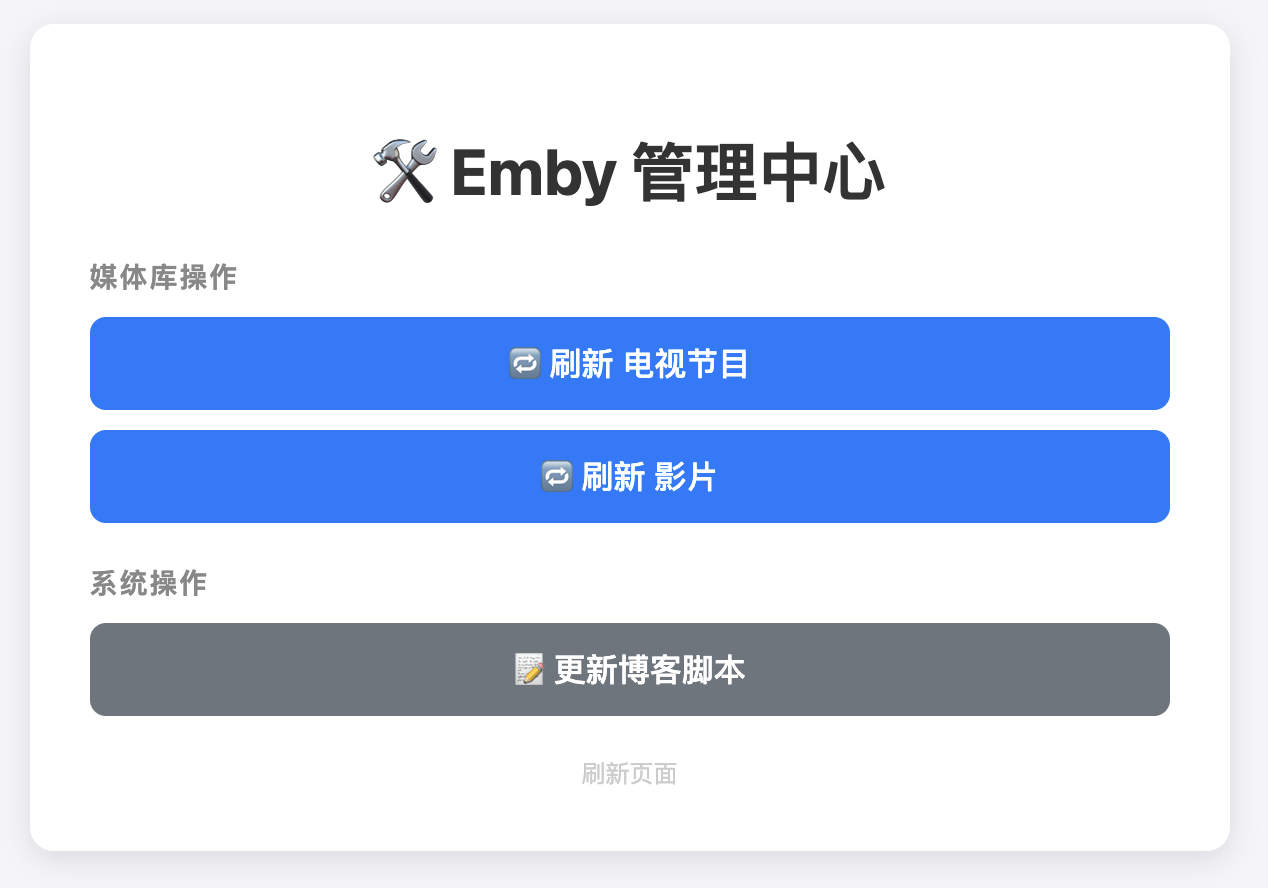
设置刮削
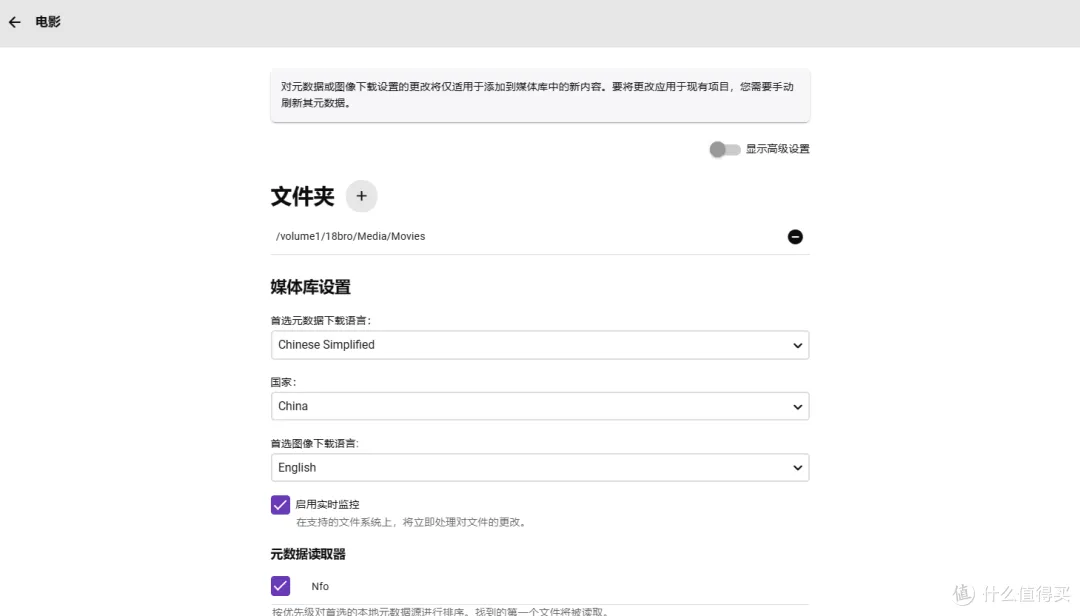
- 元数据下载语言: 选中文,这里是指刮削出来的影片资料的语言。
- 国家: 选China或者美国都没啥影响
- 图像下载语言: 我选的是英文,因为我的国语电影和外语电影分为两个库。这里可以根据自己的喜好来,如果喜欢海报图片为中文的就选中文,但是中文的海报上往往会带一大片的上映广告信息。
- 启用实时监控: 打开,当媒体库内有新文件下载完成时Emby会自动进行扫描和刮削

- 元数据读取器: 打开,读取本地NFO文件,用来读取使用本地TMM或者Radarr刮削生成的文件
- 元数据下载器: 给TMDB和The Open Movie Database打勾并点击右边的箭头把它们移到上面。TMDB优先,负责刮削元数据;OMDB负责刮削评分信息
- 从元数据下载器导入合集信息: 打开,并在下方选择要自动整理合集的数量。一般选2,就是影片在TMDB刮削到合集信息,且本地有2部以上的系列作品时自动生成合集。
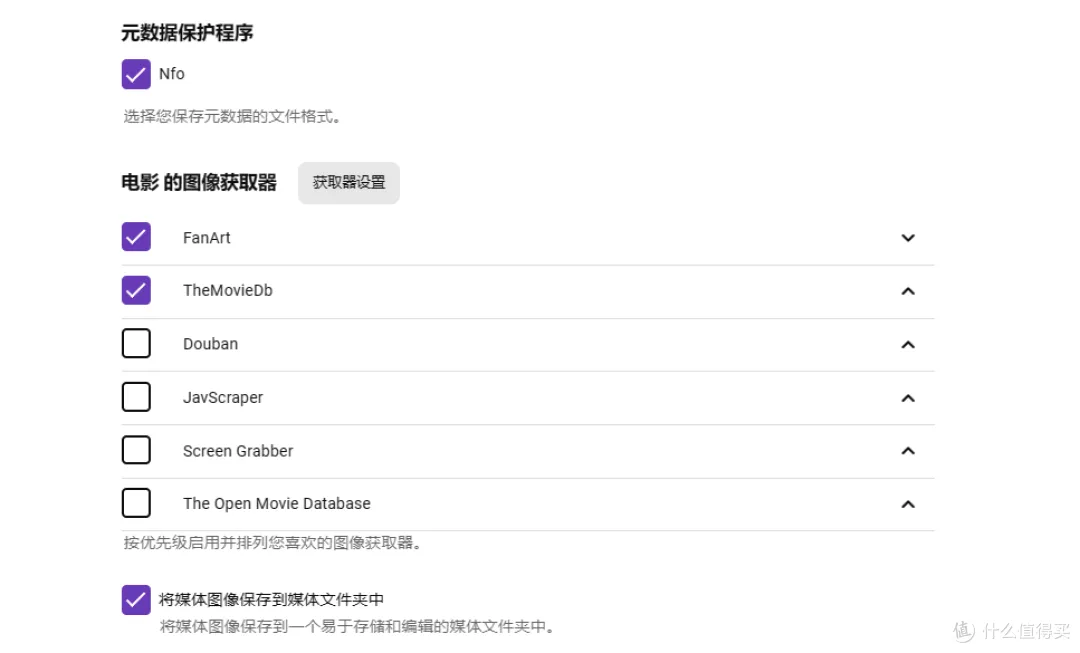
- 图像获取器: 选择TMDB和Fanart,Fanart质量较高但需要科学,TMDB改了HOST就可以获取到。万剑归宗之刮削大法!史上最全从Emby命名规则到刮削设置一条龙图文教程!
- 将媒体图像保存到文件夹中: 打勾,刮削到的图像会存在文件夹里方便查看
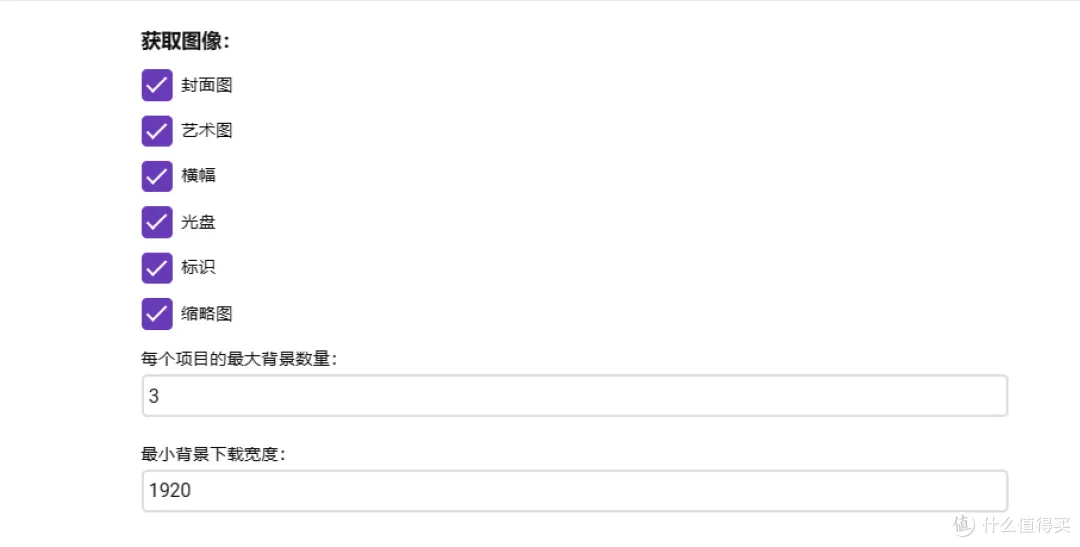
- 获取器设置: 这里设置想要抓取的图像类型,我是全部打上勾了。下面设置想要抓取的数量和图像大小,默认是1280太小了,建议修改成1920。

- 视频预览缩略图: Emby会使用FFMPEG抓取视频预览图,也就是你鼠标放在时间轴上时显示的预览图。也会显示在影片详情页的章节里。
- 字幕下载: 我不推荐使用Emby来下载字幕,但是有需求的话可以打开,这里的设置根据实际情况选择即可。

- 元数据下载器: 我是全勾上了,因为我把这几个API全部加入了强制代理。
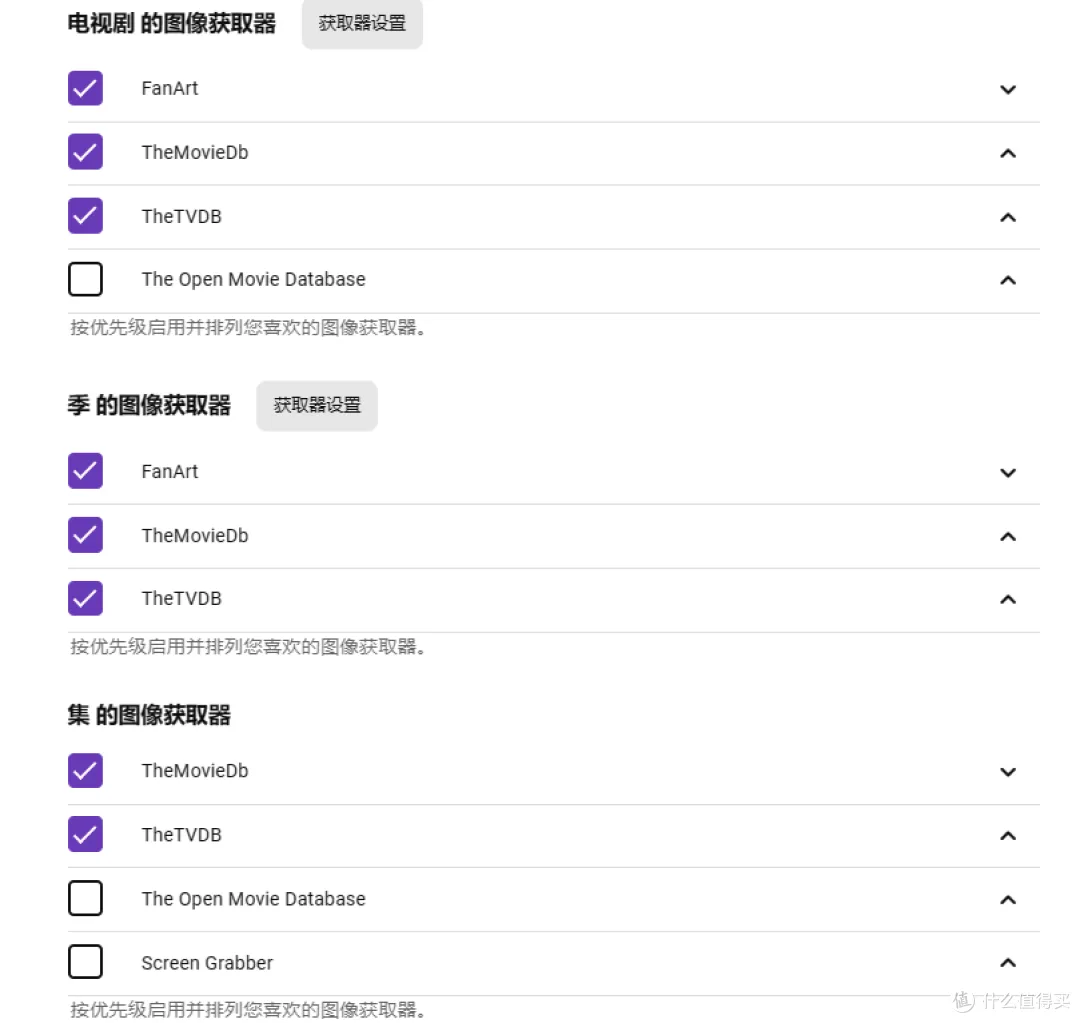
- 图像获取器: 我优先使用Fanart保证获取的质量,如果是修改HOST方式请只选用TMDB
- 获取器设置: 参照电影的设置即可
网盘资源
备注
- 脚本中
EMBY_BASE_URL需要替换为自己的emby地址 - 脚本中
EMBY_API_KEY需要替换为自己的emby api key - 脚本中
SHELL_SCRIPT_PATH需要替换为自己的博客更新脚本路径(懒得删除代码了)